Presto计算模块基本概念
https://www.iteblog.com/archives/9955.html
https://aliyuque.antfin.com/olap_platform/dtglq3/nfd5u2
https://aaaaaaron.github.io/2022/07/11/Presto-Scheduler/
:::
执行流程名词解析
首先介绍adb -xihe里每个查询的各个概念
Query: 当Presto接受一个SQL语句并执行时,会解析该SQL语句,将其转变成一个查询执行。
计算过程
Stage(逻辑)
查询执行阶段,当运行Query时,Presto根据是否需要跨worker做数据传输来将一个Query拆分成具有层级关系的多个Stage。
- 每个Stage都有id,StageId越小,这个Stage的执行顺序越靠后。
- Spark计算引擎也有Stage,不过Spark是批处理的模式,前面的Stage执行完所有数据再执行后面的Stage,前一个stage执行完再启动后一个stage。
- Presto中数据流水线(pipeline)的处理机制,一批数据走完所有的stage流程,所以在初始化的时候,所有worker上的task都是启起来的。
Task(物理):
分布式任务的执行单元,Stage只是定义了执行计划怎么划分, 接下来被调度到各个机器上去执行
- Task是节点级的并发:Stage并不会在Presto集群中实际执行,只是用来对查询计划进行管理和建模,因此Task是stage在某一个worker或者executor上的实例化
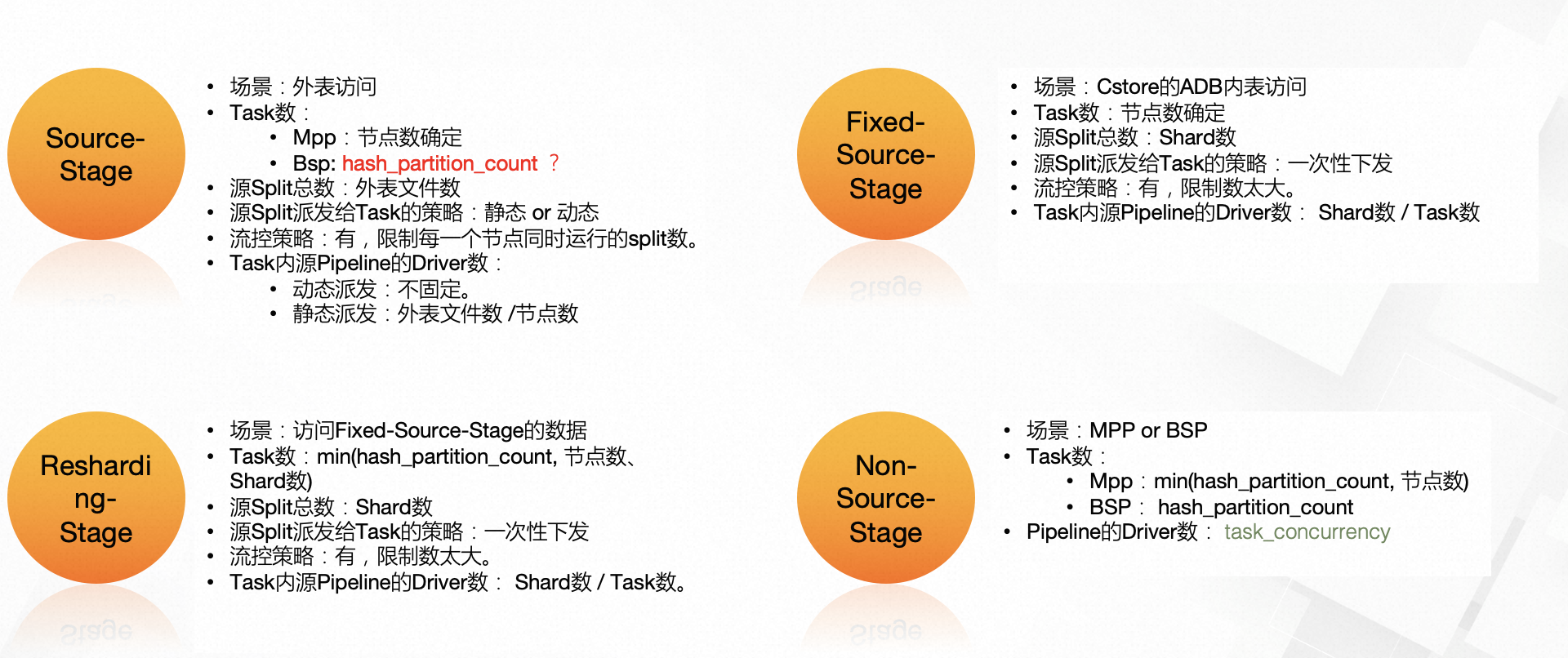
- 一个Stage对应的多个Task内部执行逻辑完全相同,对应的Task数量就是Stage的并法度,具体是根据Stage的类型(Source、Fixed、Single)以及Worker的个数来决定的。
- 从数据的视角出发,每个Task处理一个或者多个Split
- 从计算的视角出发,一个Task又被分解为一个或多个Driver。
Pipeline(逻辑):
在Task内部,每个operator的最佳并发度可能不同。所以将Task切分为若干PipeLine,每个Pipeline内部的Operator的并发度相同。
每个task会把算子执行树分成多个pipeline,每个pipeline执行stage任务的一部分操作
Task 执行 stage(PlanFragment) 的逻辑, 就是执行一组 operator, 执行 operator 的最佳并行度可能是不同的, 比如说做Tablescan的并发可以很大, 但做Final Aggregation(如Sort)的并发度只能是一;
所以一个 stage 会被切为若干 pipeline, 每个 Pipeline 由一组 Operator 组成, 这些 Operator 被设置同样的并行度. Pipeline 之间会通过 LocalExchangeOperator 来传递数据.
driver 的数量就是 pipeline 的并行度
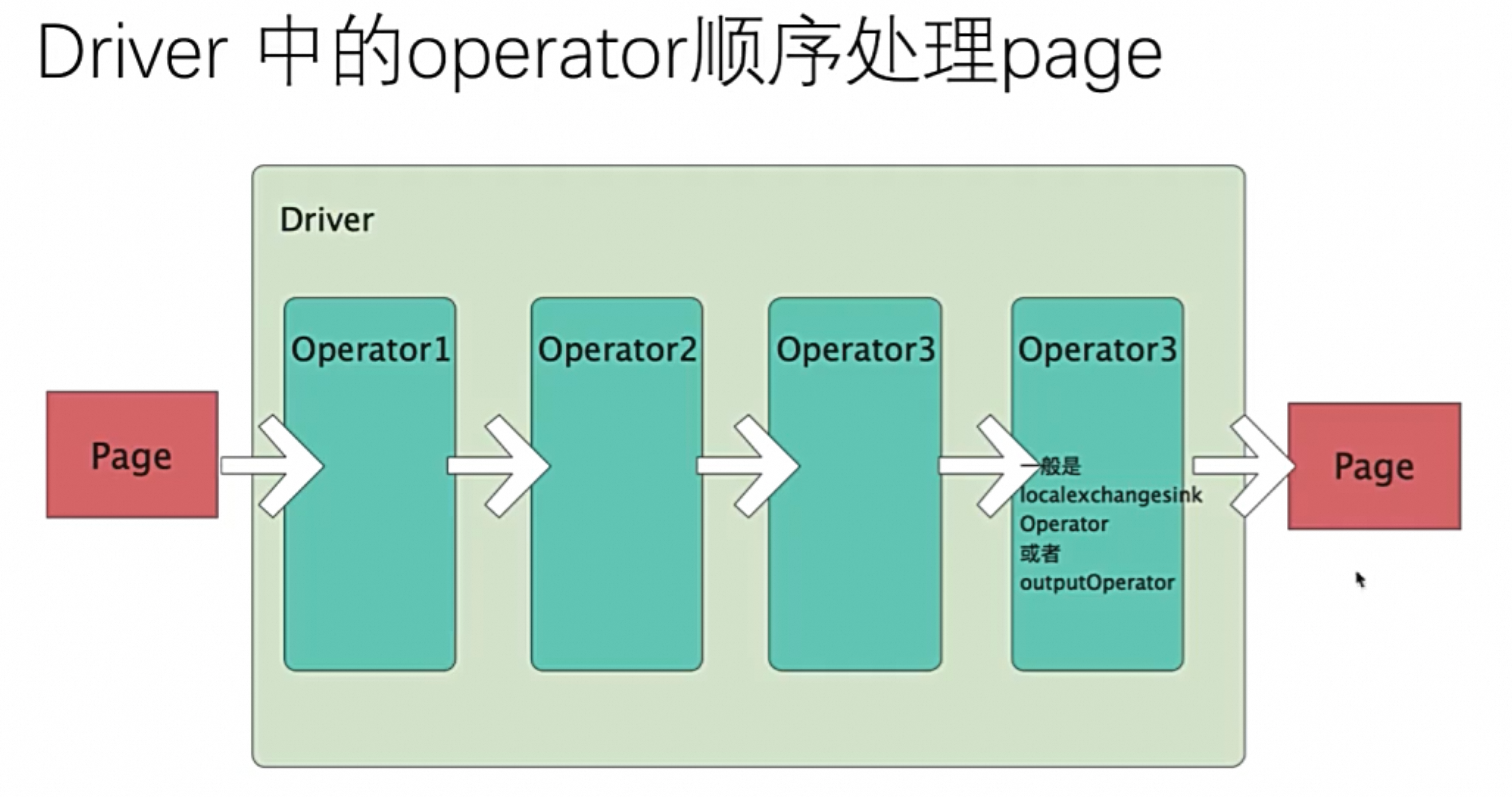
Driver(物理):
Driver是Pipeline的实例,其作用于一个Split的一系列Operator,Pipeline就是DriverFactory,用来create Driver
- Driver里不再有并行度, 每个Driver都是单线程的,一个PipeLine以实例化成多个相同的driver,driver之间是利用多线程并发运行
- 每一个driver是一串operator算子操作集合,每个 Driver 拥有一个输入和输出.
Operator
代表对一个split的一种操作。例如过滤,加权等。以Page为最小处理单位进行输入输出。
- 算子,是对数据的最小计算处理单位,每次读取/处理/输出一个page
数据过程
Split:
分片, 和 MapReduce 的 split 概念相似, 其下面包含 page
Presto Connector会将待处理的所有数据划分为若干分片让Presto读取,一个分片就是一个大的数据集中的一部分,和shard的关系?
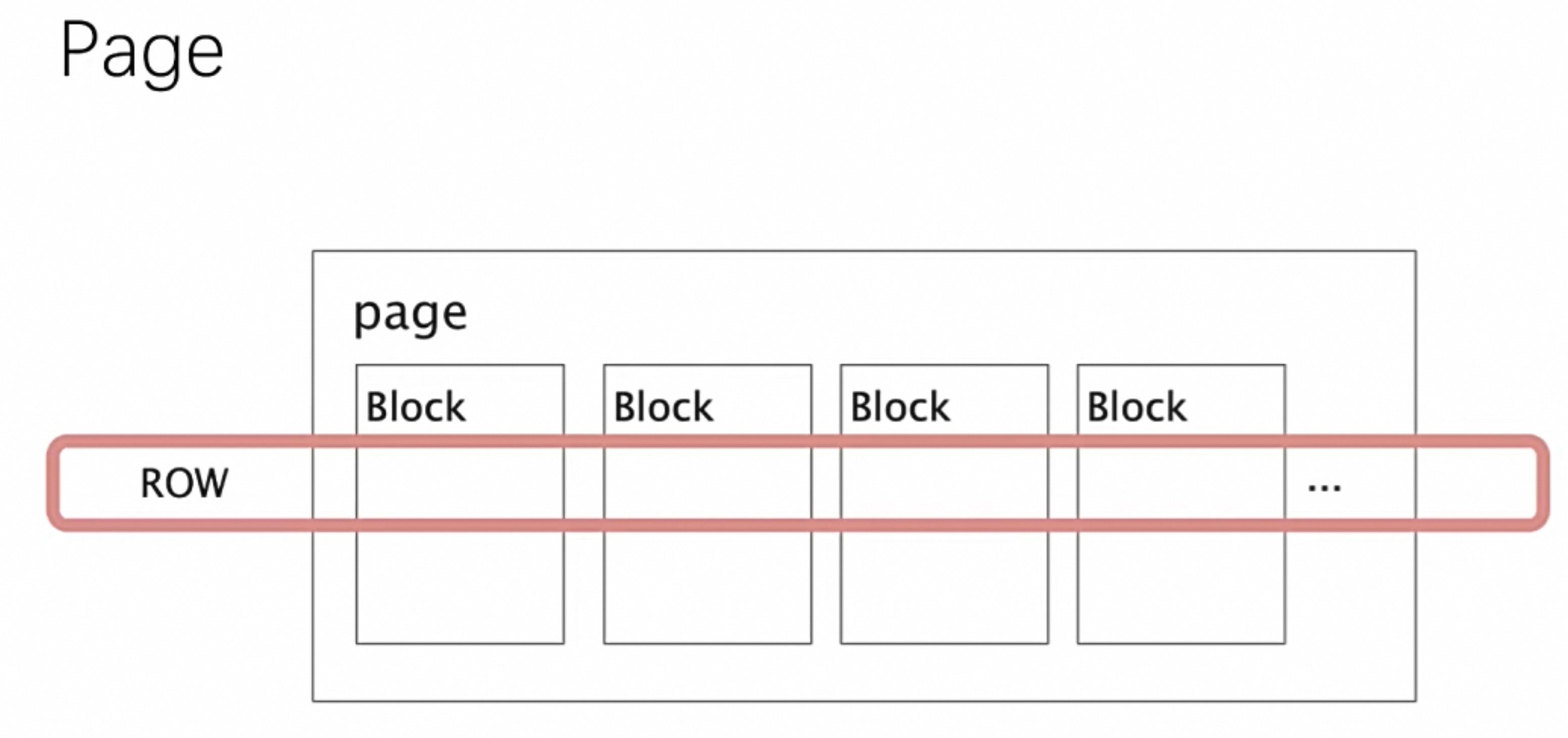
Page:
Page是Presto中处理的最小数据单元。一个Page对象包含多个Block对象。每个 Block 对象是一个字节数组, 存储一个字段(列)的若干行. 多个 Block 的横切的一行表示真实的一行数据. 一个 Page 最大 1MB, 最多 16 * 1024 行数据
Block:
是xihe底层存储时候的读写基本单元,多个Block共同组成一个Page,详见 《ADB-Block-格式梳理》
简单整体流程
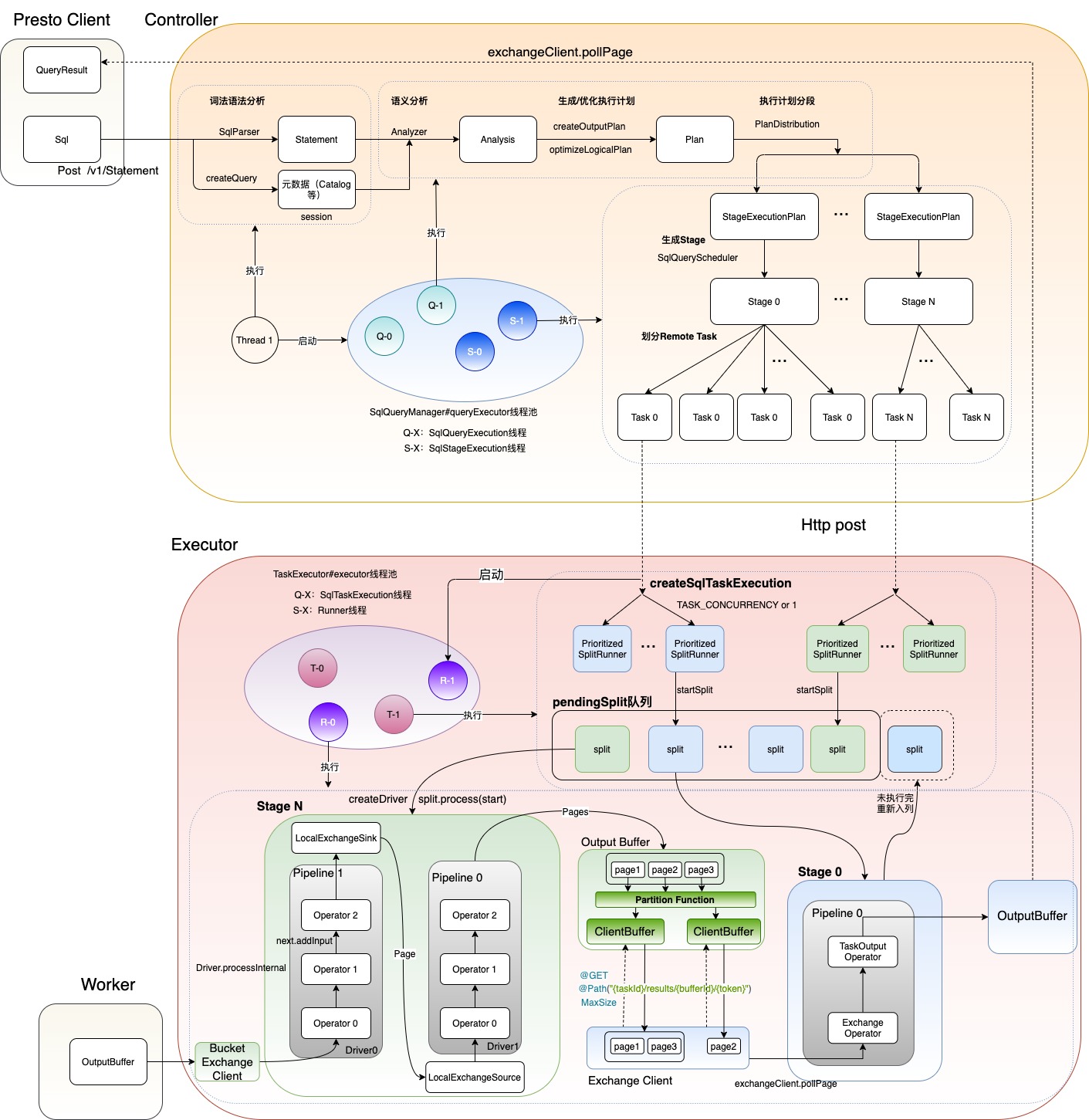
- 第一步:【Controller】接收SQL Query请求
- 将sql转换为一个statement
- 第二步:【Controller】词法与语法分析(生成AST)
- 第三步:【Controller】创建和启动QueryExecution
- 第四步:【Controller】语义分析
- 第五步:【Controller】执行计划生成和优化
- 生产逻辑计划Logic Plan
- 第六步:【Controller】为逻辑执行计划分段
- Plan根据是否有数据的Shuffle 来生成 Fragment
- 第七步:【Controller】创建SqlStageExecution
- 把Fragment 按照是否需要跨worker传输数据划分成Stage
- 第八步:【Controller】Stage调度-生成HttpRemoteTask并分发到Worker
- Stage在逻辑上划分为一系列Task实例,并交给Work执行
- Task是Stage的实例,Task是Stage的并发度
- 一个Task被处理多个数据分片:Spilt
- 一个Task被切分为多个Pipeline(考虑到不同的Oprator并发度不同)
- 第九步:【Worker】在Worker上执行任务,生成Query结果
- 一个Driver是作用于一个Spilt的一串Operator的集合,负责执行Pipeline
- 一个Pipeline对应多个Driver,每个Driver串行执行Operator
- 第十步:【Controller】结果返回
关键信息
Stage间在Task维度Shuffle,通过RemoteExchange表示
Stage内有多个Task,task个数由hash_partition_count决定
Task内在Pipeline间Shuffle,通过LocalExchange表示
Pipeline内有多个Driver,driver个数由task_concurrency决定
Page是xihe的数据,从存储的Block读出来转换过去,然后Query跟存储关联的是TableScan
一个Page包含多个Block对象,如下图所示
- 一个Driver可以被认为是串行执行一条pipeline,并且按照operator的顺序去处理page
- 如下图所示:
- 一个Stage 拆解成fragement后的执行流程
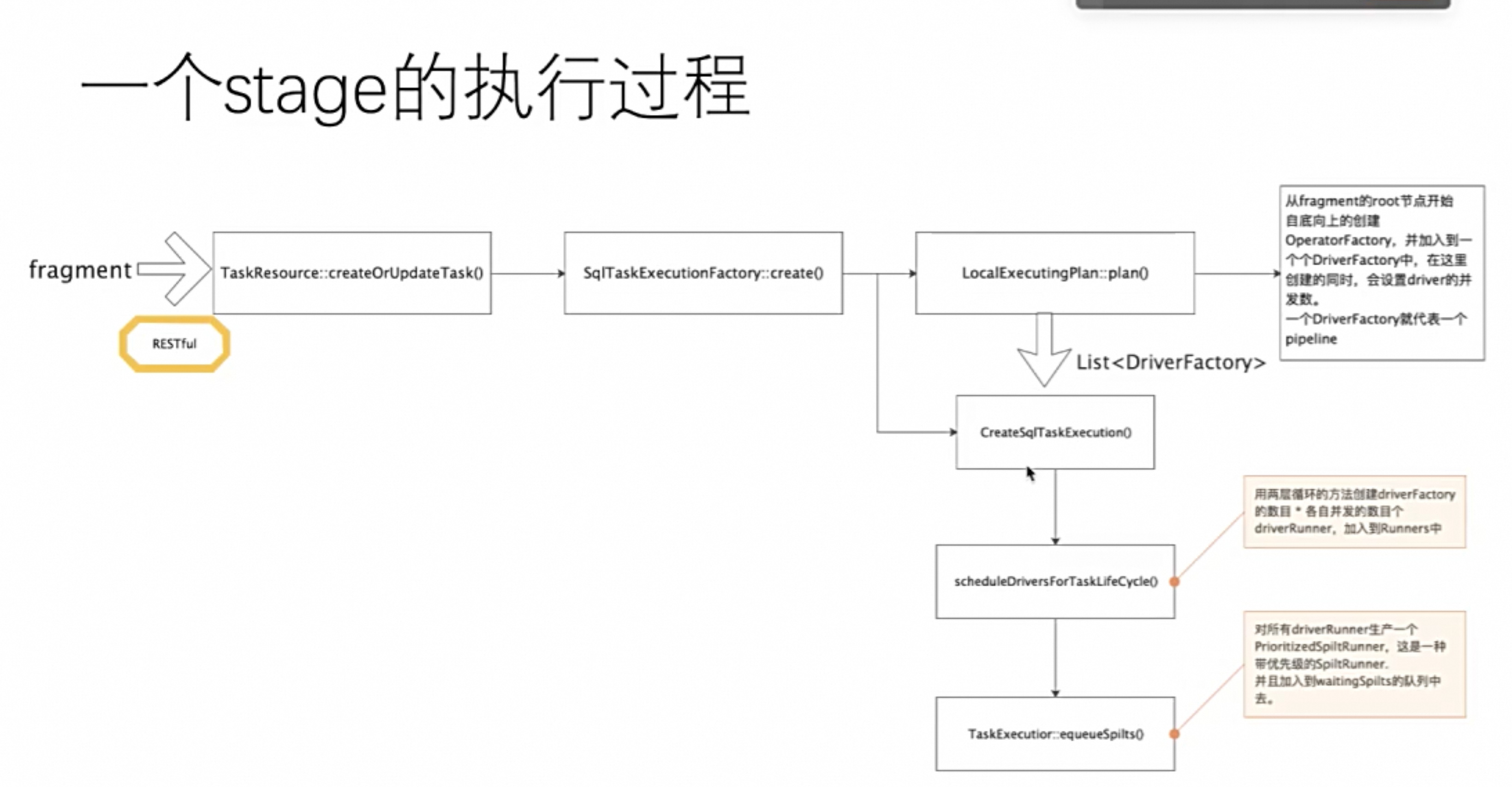
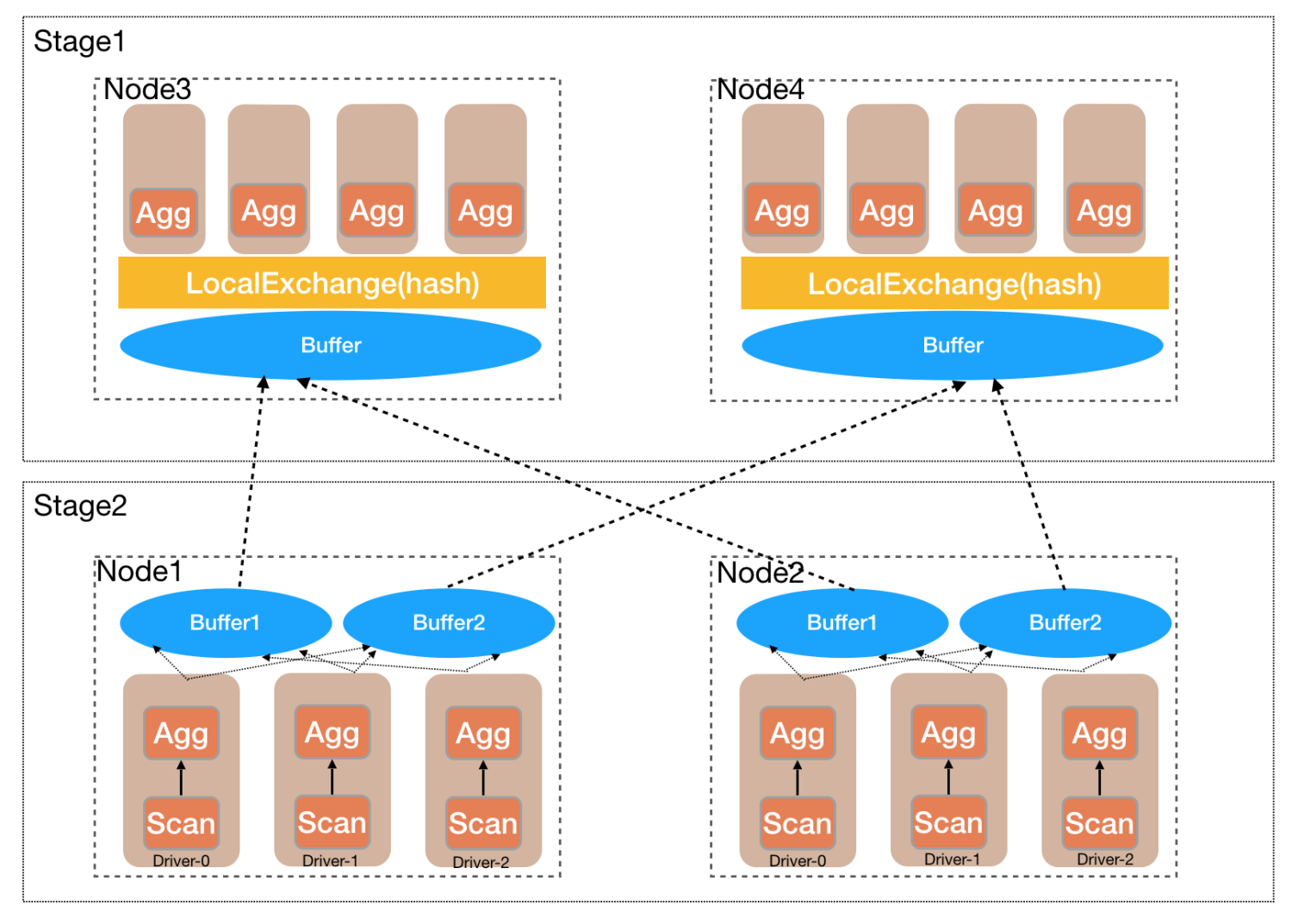
从Worker的视角考虑各个粒度
创建Task
当Stage Plan下发到worker 后
worker会通过SqlTaskExecutionFactory#createTask方法创建Thread个Task并发
在SqlTaskManager中,管理着一个taskid与task任务对应的映射表
ConcurrentHashMap<QueryId, Set<TaskId>>
其中taskid由sql的查询id与stageid唯一组成。
Task的创建方式是依靠CacheBuilder.newBuilder().build的load动态加载,非常适合presto从自下而上,或者自上而下等调度方式。这样task的创建,完全由controller控制,非常方便,这里不多做诠释了。
Spilt下发
创建Driver
一个Task对应多个Pipeline(通过DriverFactor),每个Pipeline有多个Driver作为其并发度,Driver就是一个最小的调度和执行的实体,其中有多个Operator算子
Driver的并发调度方式如下所示:
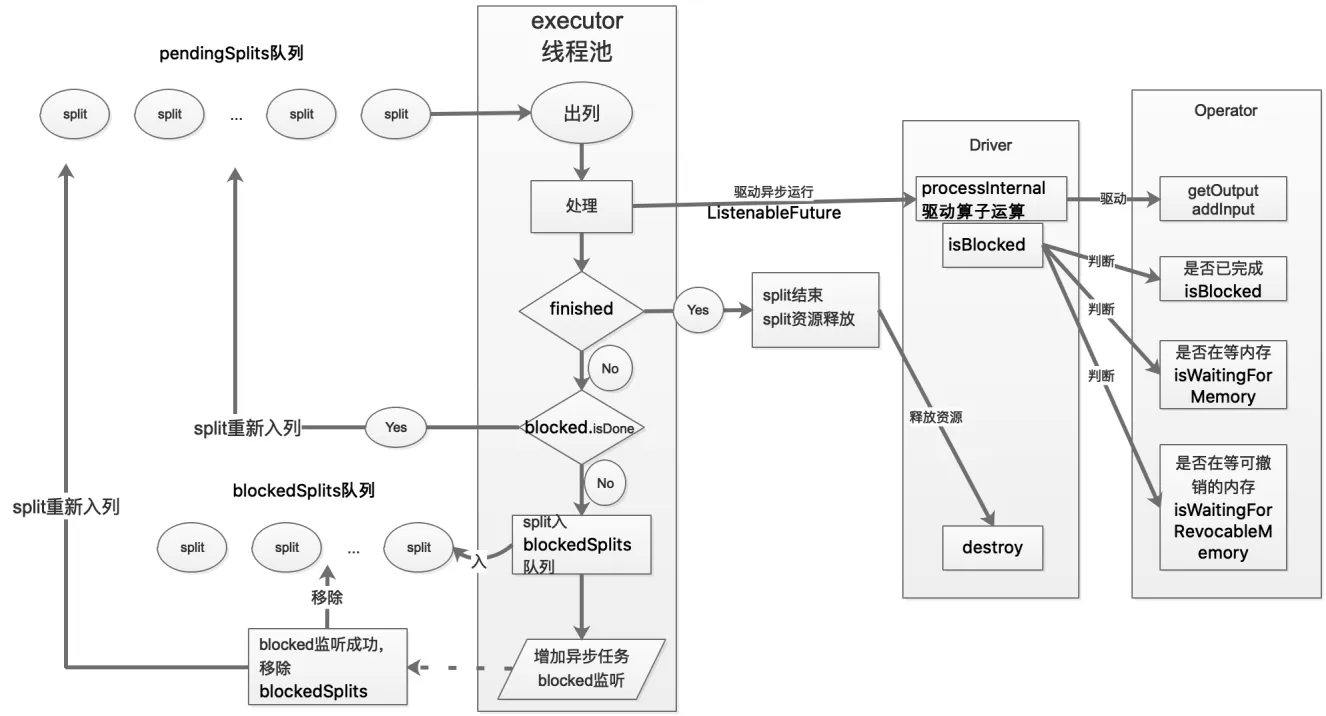
因此并发可以分成两个维度
- stage/task 级别并发:
- driver级别并发
详见图:
转载无需注明来源,放弃所有权利