分布式Join方式的简单原理
优化器会进行代价估计(有时候不一定准确),具体选择使用哪种join方式
参考文档:
单机join的几种方式
- Hash Join:在右表上根据等值 Join 列建立哈希表,左表流式的利用哈希表进行 Join 计算,它的限制是只能适用于等值 Join。
- Nest Loop Join:通过两个 for 循环,很直观,也很慢 。然后它适用的场景就是不等值的 Join,例如:大于小于或者是需要求笛卡尔积的场景。它是一个通用的 Join 算子,但是性能表现差。
作为分布式的 MPP 数据库,在 Join 的过程中是需要进行数据的 Shuffle。数据需要进行拆分调度,才能保证最终的 Join 结果是正确的。举个简单的例子,假设关系 S 和 R 进行 Join,N 表示参与 Join 计算的节点的数量;T 则表示关系的 Tuple 数目。
目前Presto主要使用的是hash join
Presto中join的几种方式
Hash Join
Presto 的hash join 将join操作中涉及的这两个表称为构建表(Build Table)和探测表(Probe Table),其区别如下
- build端:两表(或者子查询)做Hash Join时,其中一张表(子查询)的数据会构建成Hash表, 通常,在读取probe表之前必须完整读取构build表。
- probe端:Hash Join的另一边,主要是读取数据然后和build端的Hash表进行匹配,一旦build表被读取并存储在内存中,probe表就会被逐行读取。 从探测表读取的每一行都将根据 join 条件 与build表进行连接。
Presto 有一些基于成本的优化器,它们可以重新排序连接以将最小的表(即构建表)保留在右侧,以便它可以放入内存中,因此在执行计划正确的情况下,小表是build端,大表是probe端。
其java 伪代码如下所示:
1 | Map<Integer, List<S>> index = new Hashtable<>(); |
Hash Join 算法的最坏情况时间复杂度是 O(n²),但平均情况下预计为 O(n)。
Nested Loop Join
幽默连接算法,时间复杂度为 O(n²),因为它必须将探测表中的每一行与构建表中的每一行连接起来,因此,不建议在没有连接条件的情况下连接两个大表。
分布式join的shuffle方式
join 大概可以分为五种可能的形式:
- 两个表join的key不是分布的key,这样的话需要加两个exchange算子来做数据的reshuffle (性能差)
- 左表的数据按照joinkey分布,这样对右边的数据做重分布就可以了
- 右表的数据量比较少,直接把右表的数据做一次BroadCast(BroadCast Join)
- 在存储计算不分离的情境下,比如右表(例如维度表)本来就在本地,这种情况下,不需要做网络开销,直接从本地拉取
- 最理想的情况下,左右两个表的joinkey都是分布的key,这样的话直接做local join

Broadcast Join
左表数据不移动,右表数据发送到左表数据的扫描****节点,适合一张较小的表和一张大表进行join
它要求把右表全量的数据都发送到左表上,即每一个参与 Join 的节点,它都拥有右表全量的数据,也就是 T(R)。
它适用的场景是比较通用的,同时能够支持 Hash Join 和 Nest loop Join,它的网络开销 N * T(R)。

Shuffle Join
一旦小表数据量较大,此时就不再适合进行广播分发。这种情况下左右表数据根据分区,计算的结果发送到不同的分区节点上,将两张表分别按照join key进行重新组织分区,这样就可以将join分而治之,划分为很多小join
当进行 Hash Join 时候,可以通过 Join 列计算对应的 Hash 值,并进行 Hash 分桶。
它的网络开销则是:T(S) + T(R),但它只能支持 Hash Join,因为它是根据 Join 的条件也去做计算分桶的。
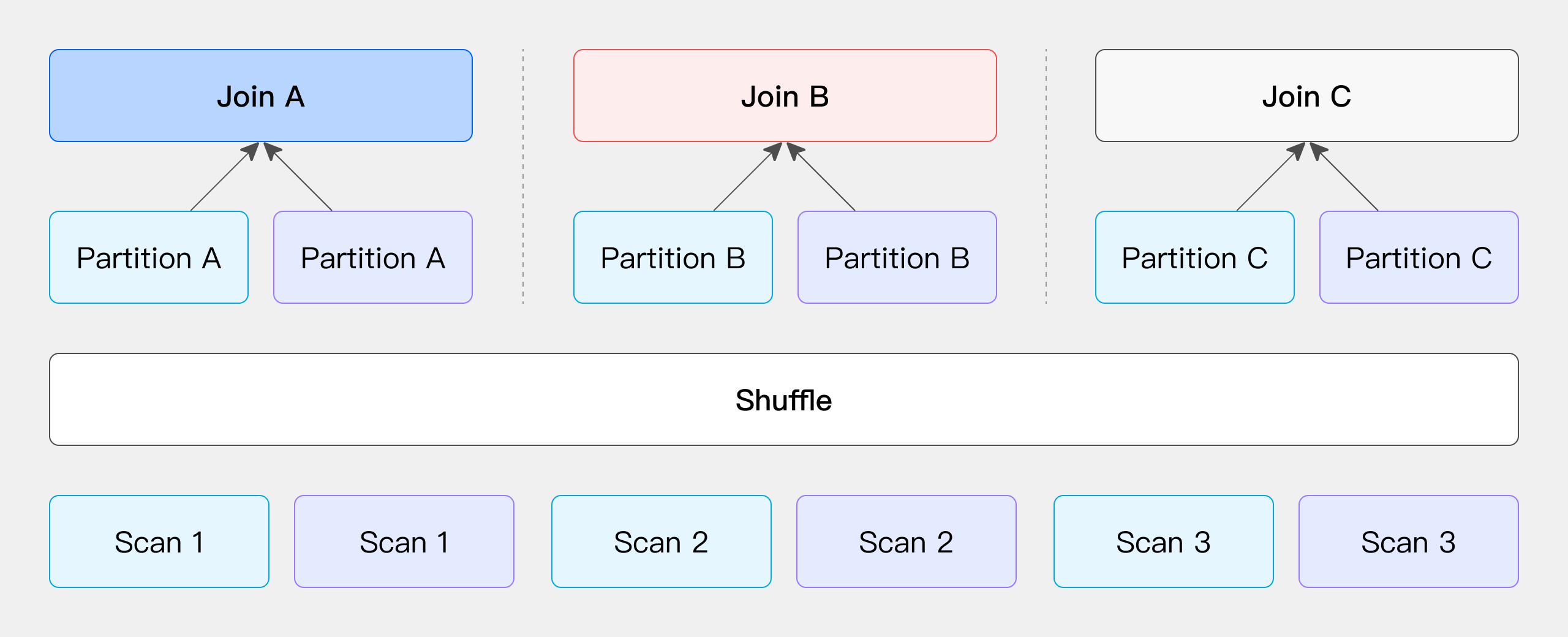
Bucket Shuffle Join
Doris 的表数据本身是通过 Hash 计算分桶的,所以就可以利用表本身的分桶列的性质来进行 Join 数据的 Shuffle。假如两张表需要做 Join,并且 Join 列是左表的分桶列,那么左表的数据其实可以不用去移动右表通过左表的数据分桶发送数据就可以完成 Join 的计算。
它的网络开销则是:T(R)相当于只 Shuffle 右表的数据就可以了。
几种 Shuffle 方式对比
| Shuffle 方式 | 网络开销 | 物理算子 | 适用场景 |
|---|---|---|---|
| BroadCast | N * T(R) | Hash Join / Nest Loop Join | 通用 |
| Shuffle | T(S) + T(R) | Hash Join | 通用 |
| Bucket Shuffle | T(R) | Hash Join | Join 条件中存在左表的分布式列,且左表执行时为单分区 |
N:参与 Join 计算的 Instance 个数
T(关系) : 关系的 Tuple 数目
转载无需注明来源,放弃所有权利