1. 矩阵(稀疏矩阵)压缩存储(3种方式)
数据结构中,提供针对某些特殊矩阵的压缩存储结构。
存储矩阵的一般方法是采用二维数组,其优点是可以随机地访问每一个元素,因而能够容易实现矩阵的各种运算。
对于稀疏矩阵,它通常具有很大的维度,有时甚大到整个矩阵(零元素)占用了绝大部分内存
采用二维数组的存储方法既浪费大量的存储单元来存放零元素,又要在运算中浪费大量的时间来进行零元素的无效运算。因此必须考虑对稀疏矩阵进行压缩存储(只存储非零元素)。
这里所说的特殊矩阵,主要分为以下3类:
- 含有大量相同数据元素的矩阵,比如对称矩阵;
 因此可以使用一维数组存储对称矩阵。由于矩阵中沿对角线两侧的数据相等,因此数组中只需存储对角线一侧
因此可以使用一维数组存储对称矩阵。由于矩阵中沿对角线两侧的数据相等,因此数组中只需存储对角线一侧 - 含有大量 0 元素的矩阵,比如稀疏矩阵、上(下)三角矩阵;
 上(下)三角矩阵采用对称矩阵的方式存储上(下)三角的数据(元素 0 不用存储)
上(下)三角矩阵采用对称矩阵的方式存储上(下)三角的数据(元素 0 不用存储) - 稀疏矩阵 如果矩阵中分布有大量的元素 0,即非 0 元素非常少,这类矩阵称为稀疏矩阵。

压缩存储稀疏矩阵的一个简单而朴素的方法是:只存储矩阵中的非 0 元素,与前面的存储方法不同,稀疏矩阵非 0 元素的存储需同时存储该元素所在矩阵中的行标和列标。
2. 稀疏矩阵压缩的主要方法
2.1 坐标法 COO
这种存储格式比较简单易懂,每一个元素需要用一个三元组来表示,分别是(行号,列号,数值),对应上图右边的一列。这种方式简单,但是记录单信息多(行列),每个三元组自己可以定位,因此空间不是最优。
- 采用三元组
(row, col, data)(或称为ijv format)的形式来存储矩阵中非零元素的信息 - 三个数组
row、col和data分别保存非零元素的行下标、列下标与值(一般长度相同) - 故
coo[row[k]][col[k]] = data[k],即矩阵的第row[k]行、第col[k]列的值为data[k]
适用场景
- 主要用来创建矩阵,因为coo_matrix无法对矩阵的元素进行增删改等操作
- 一旦创建之后,除了将之转换成其它格式的矩阵,几乎无法对其做任何操作和矩阵运算
优缺点
①优点
- 转换成其它存储格式很快捷简便(
tobsr()、tocsr()、to_csc()、to_dia()、to_dok()、to_lil()) - 能与CSR / CSC格式的快速转换
- 允许重复的索引(例如在1行1列处存了值2.0,又在1行1列处存了值3.0,则转换成其它矩阵时就是2.0+3.0=5.0)
②缺点
- 不支持切片和算术运算操作
- 如果稀疏矩阵仅包含非0元素的对角线,则对角存储格式(DIA)可以减少非0元素定位的信息量
- 这种存储格式对有限元素或者有限差分离散化的矩阵尤其有效
2.2 行压缩格式 Compressed Sparse Row (CSR)
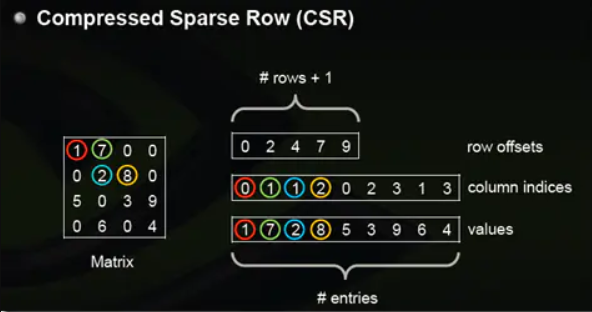
这是经常用的一种,我们会经常在一些标准的线性代数库或者数值运算库中看到此方式存储;CSR是比较标准的一种,也需要三类数据来表达:数值,列号,以及行偏移。CSR不是三元组,而是整体的编码方式。数值和列号与COO一致,表示一个元素以及其列号,行偏移表示某一行的第一个元素在values里面的起始偏移位置。
如上图中,第一行的第一个元素1在values中是第0个, 所以是0偏移,第二行元素第一个元素2是2偏移,第三行第一个元素5是4偏移,第4行第一个元素6是7偏移。在行偏移的最后补上矩阵总的元素个数,本例中一共是9个非零元素。
主要特征如下:
csr_matrix是按行对矩阵进行压缩的
通过
indices,indptr,data来确定矩阵。data表示矩阵中的非零数据对于第
i行而言,该行中非零元素的列索引为indices[indptr[i]:indptr[i+1]]可以将
indptr理解成利用其自身索引i来指向第i行元素的列索引根据
[indptr[i]:indptr[i+1]],我就得到了该行中的非零元素个数,如若
index[i] = 3且index[i+1] = 3,则第i行的没有非零元素若
index[j] = 6且index[j+1] = 7,则第j行的非零元素的列索引为indices[6:7]得到了行索引、列索引,相应的数据存放在:
data[indptr[i]:indptr[i+1]]
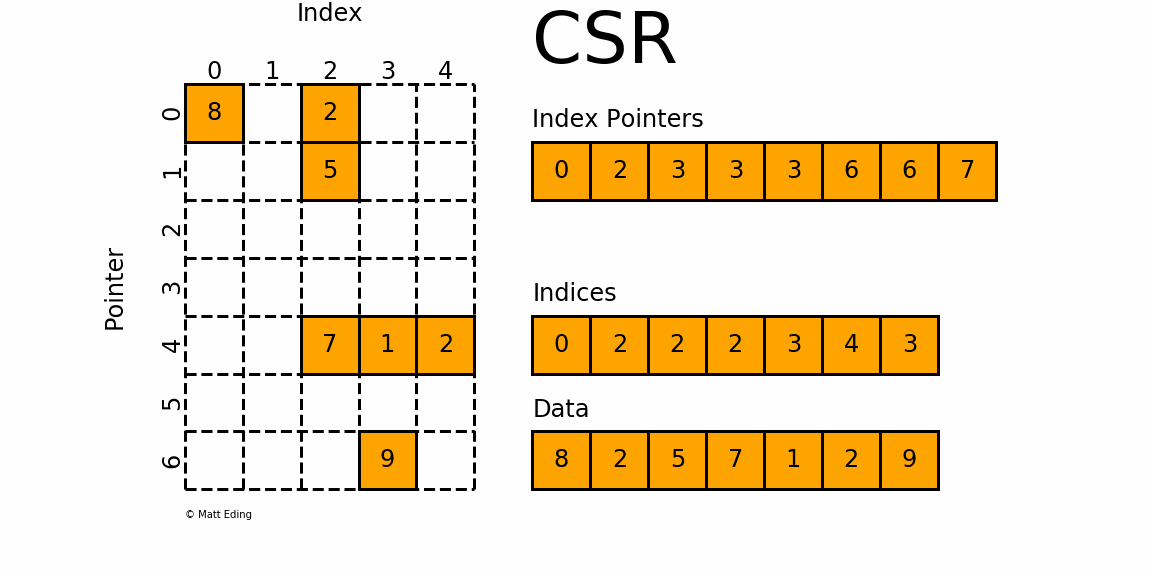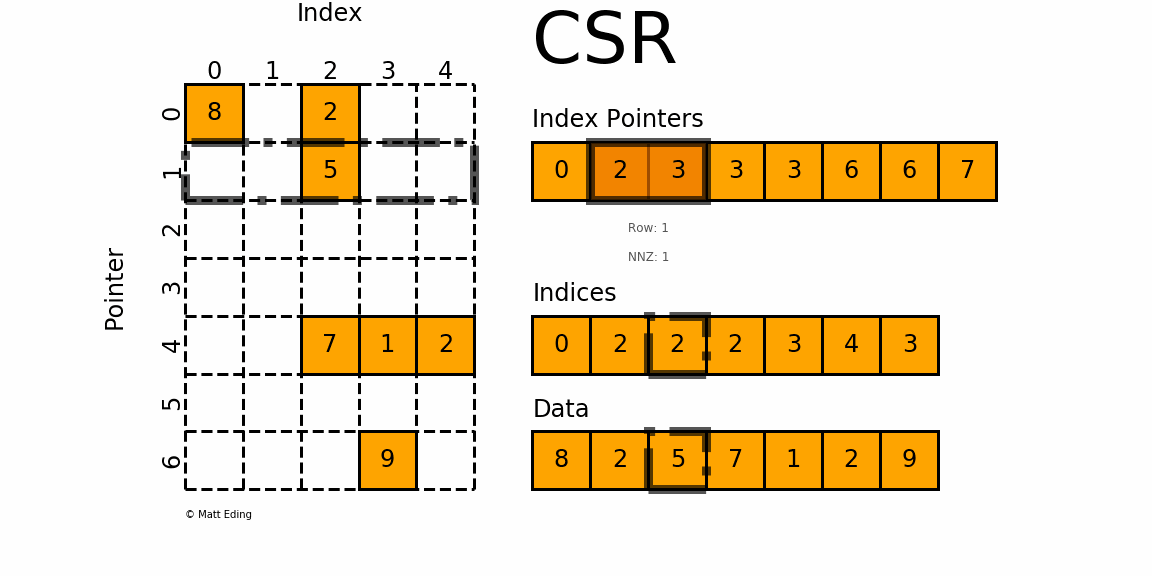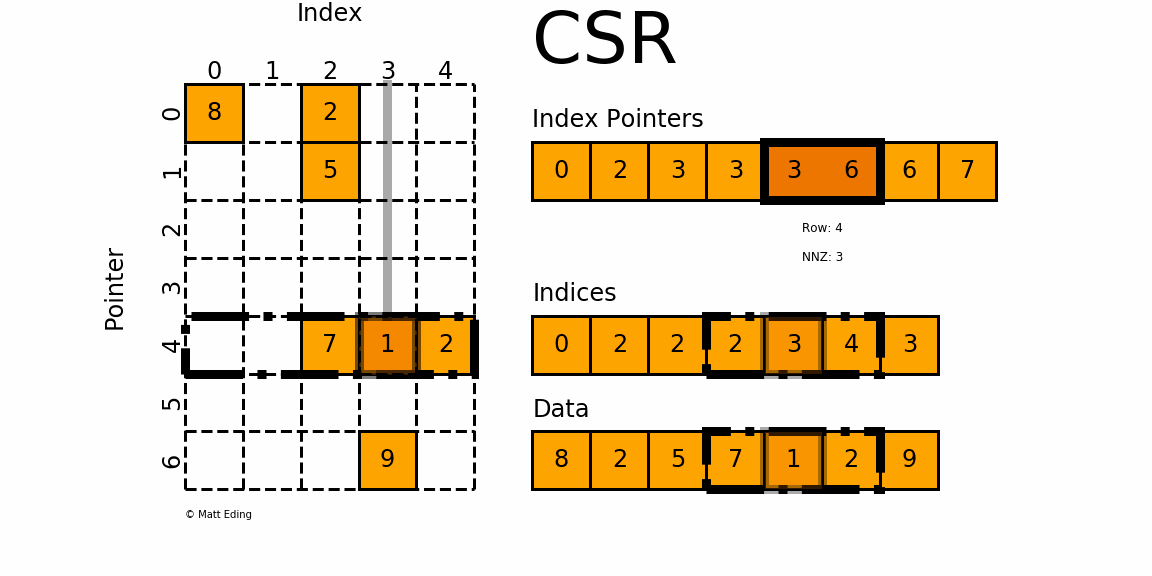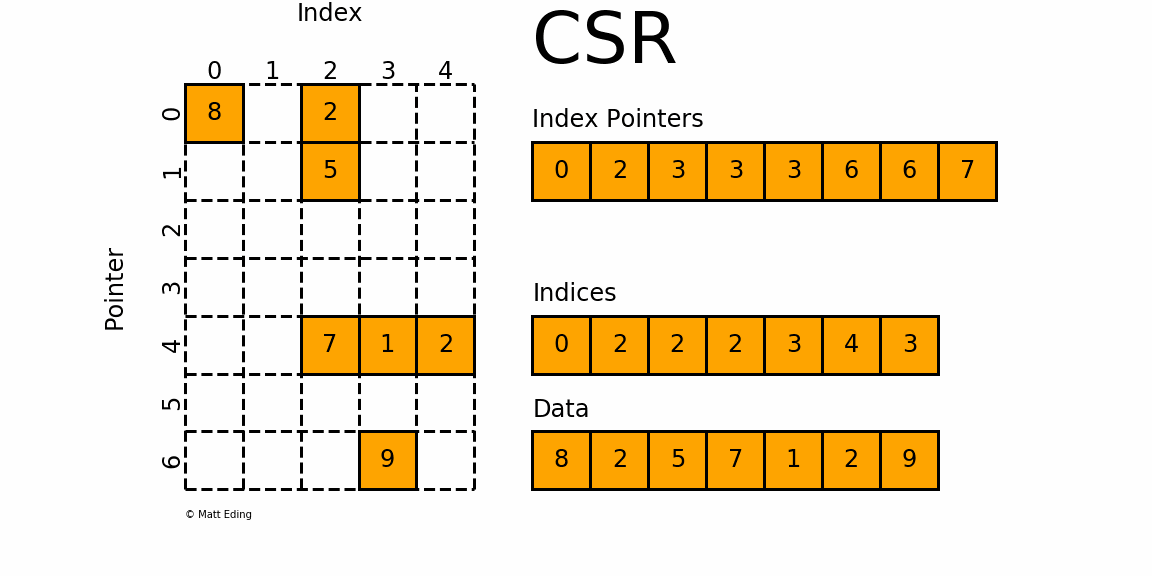
对于矩阵第
0行,我们需要先得到其非零元素列索引由
indptr[0] = 0和indptr[1] = 2可知,第0行有两个非零元素。它们的列索引为
indices[0:2] = [0, 2],且存放的数据为data[0] = 8,data[1] = 2因此矩阵第
0行的非零元素csr[0][0] = 8和csr[0][2] = 2对于矩阵第
4行,同样我们需要先计算其非零元素列索引由
indptr[4] = 3和indptr[5] = 6可知,第4行有3个非零元素。它们的列索引为
indices[3:6] = [2, 3,4],且存放的数据为data[3] = 7,data[4] = 1,data[5] = 2因此矩阵第
4行的非零元素csr[4][2] = 7,csr[4][3] = 1和csr[4][4] = 2优缺点
①优点
- 高效的稀疏矩阵算术运算
- 高效的行切片
- 快速地矩阵矢量积运算
②缺点
- 较慢地列切片操作(可以考虑CSC)
- 转换到稀疏结构代价较高(可以考虑LIL,DOK)
2.3列压缩格式 Compressed Sparse Column (CSC)
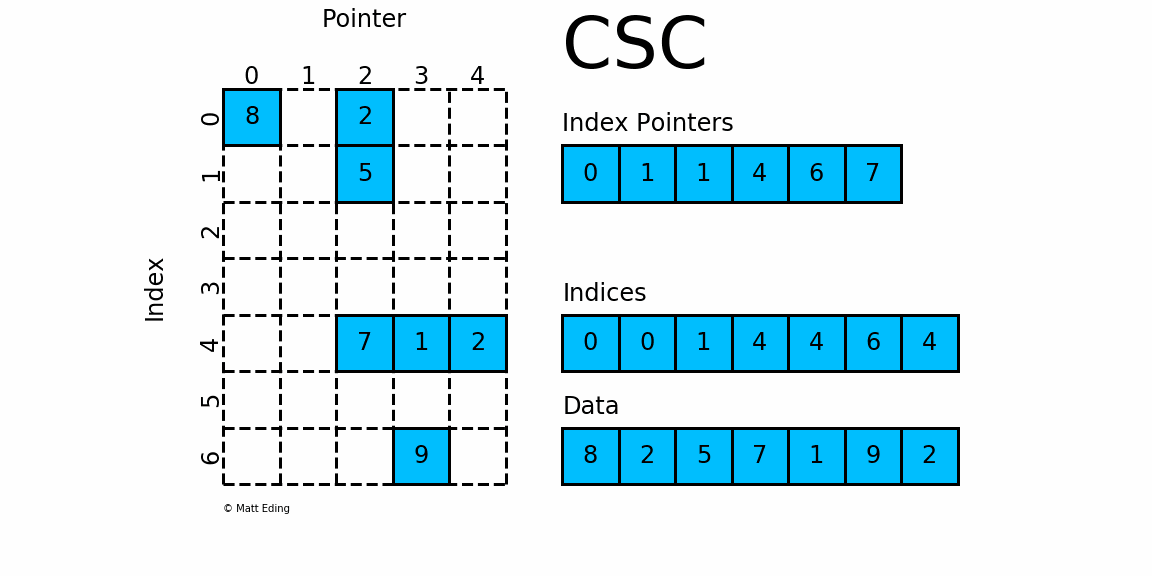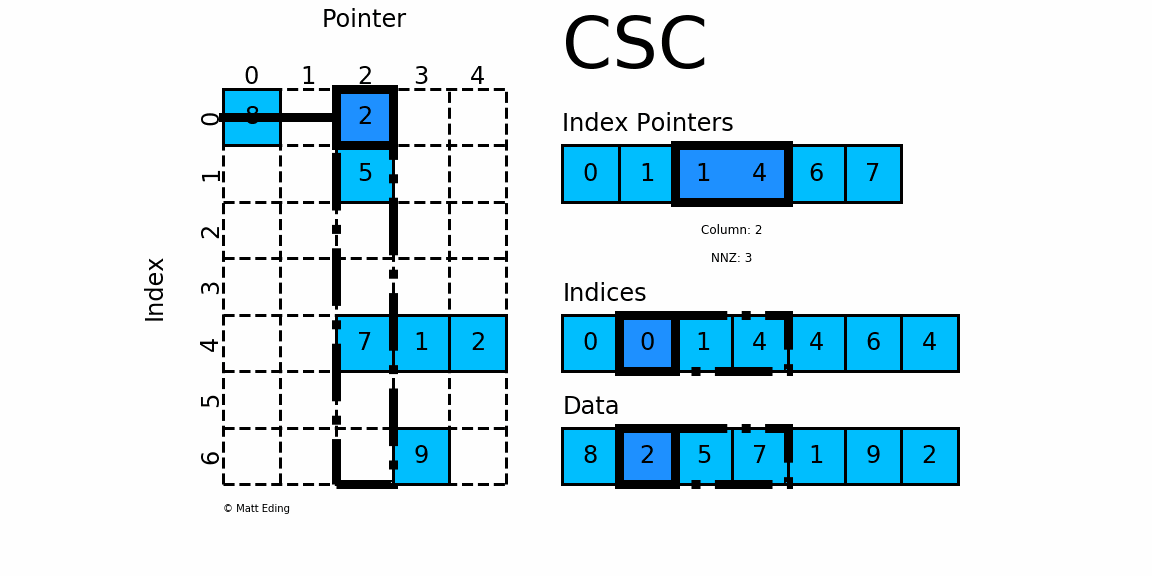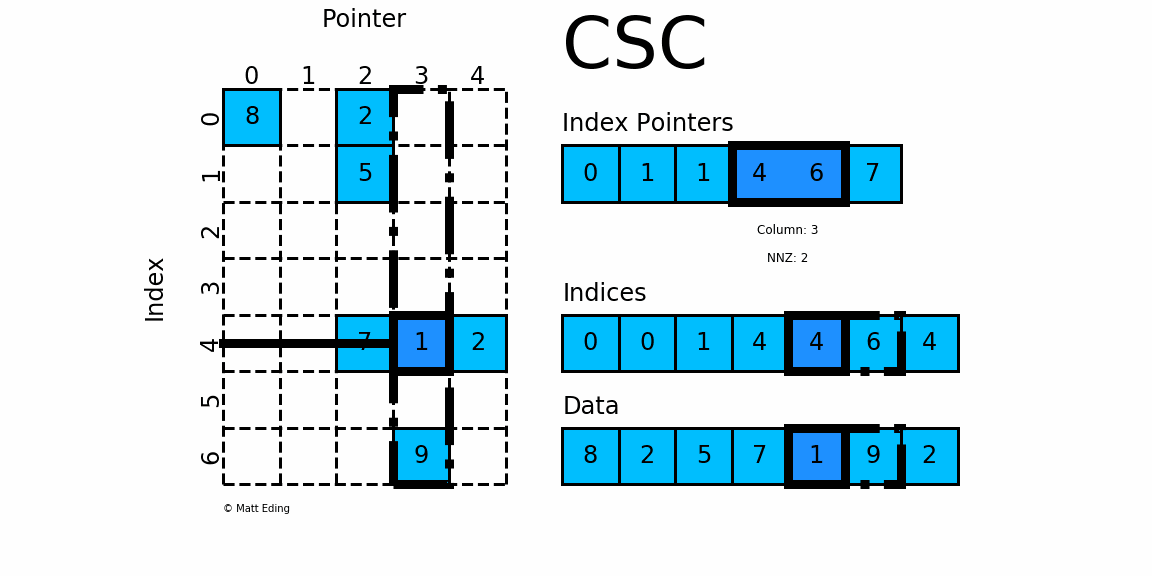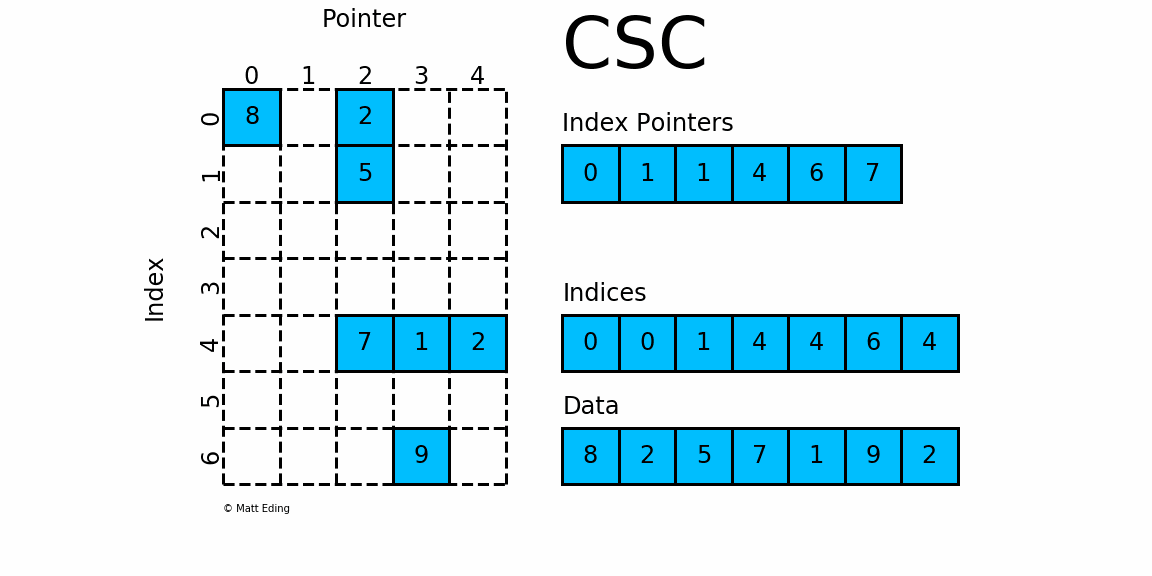
CSC是和CSR相对应的一种方式,即按列压缩的意思。
1 | [[1 7 0 0] |
以上图中矩阵为例:
1 | Column Offsets:[0 2 5 7 9] |
Values中的元素要按列写, 跟COO和CSR不同, 指定了Values的元素顺序之后就可以写Row Index, 然后根据每一列第一个元素在Values中的位置确定偏移量Column Offsets. 如第一列第一个元素1是0偏移, 第二列第一个元素7是2偏移, 第三列第一个元素8是5偏移, 第四列第一个元素9是7偏移, 共9个元素.
主要特征如下:
csc_matrix是按列对矩阵进行压缩的
通过
indices,indptr,data来确定矩阵,可以对比CSRdata表示矩阵中的非零数据对于第
i列而言,该行中非零元素的行索引为indices[indptr[i]:indptr[i+1]]可以将
indptr理解成利用其自身索引i来指向第i列元素的列索引根据
[indptr[i]:indptr[i+1]],我就得到了该行中的非零元素个数,如若
index[i] = 1且index[i+1] = 1,则第i列的没有非零元素若
index[j] = 4且index[j+1] = 6,则第j列的非零元素的行索引为indices[4:6]得到了列索引、行索引,相应的数据存放在:
data[indptr[i]:indptr[i+1]]
对于矩阵第 0 列,我们需要先得到其非零元素行索引
- 由
indptr[0] = 0和indptr[1] = 1可知,第0列行有1个非零元素。 - 它们的行索引为
indices[0:1] = [0],且存放的数据为data[0] = 8 - 因此矩阵第
0行的非零元素csc[0][0] = 8
对于矩阵第 3 列,同样我们需要先计算其非零元素行索引
- 由
indptr[3] = 4和indptr[4] = 6可知,第4行有2个非零元素。 - 它们的行索引为
indices[4:6] = [4, 6],且存放的数据为data[4] = 1,data[5] = 9 - 因此矩阵第
i行的非零元素csr[4][3] = 1,csr[6][3] = 9
2.4 Block Sparse Row Matrix (分块压缩稀疏行格式)(BSR)
基于行的块压缩,与csr类似,都是通过
data,indices,indptr来确定矩阵与csr相比,只是data中的元数据由0维的数变为了一个矩阵(块),其余完全相同
块大小
blocksize块大小
(R, C)必须均匀划分矩阵(M, N)的形状。R和C必须满足关系:
M % R = 0和N % C = 0适用场景及优点参考csr
参考(抄袭)
转载无需注明来源,放弃所有权利